Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
IRJET- Cross Modal Localization of Moments in Video by IRJET Journal ...
ViFi-Loc: Multi-modal Pedestrian Localization using GAN with Camera ...
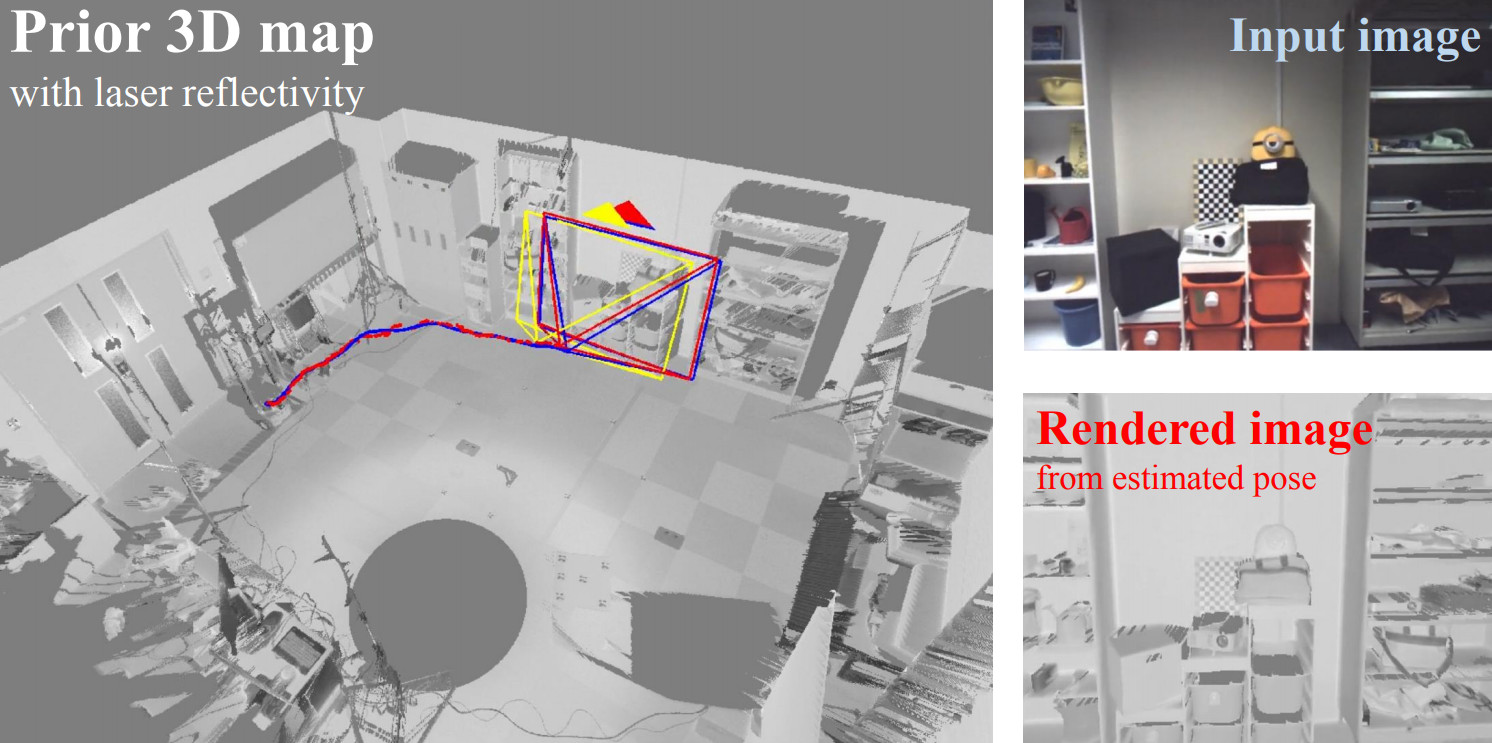
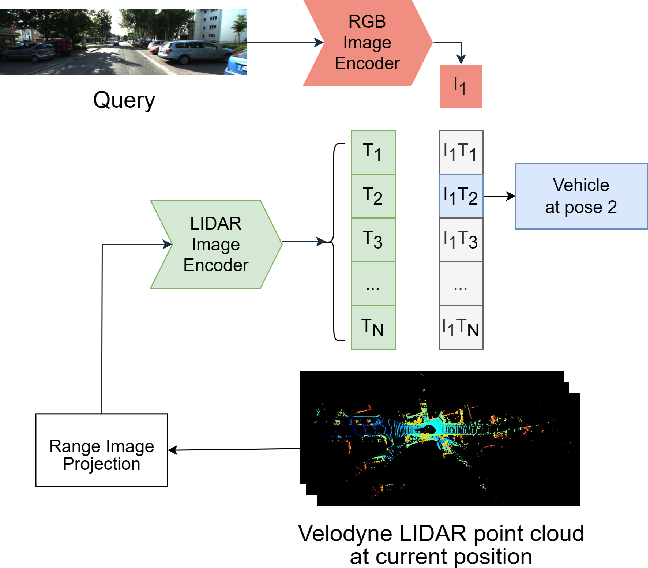
Figure 2 from Cross-Modal Monocular Localization in Prior LiDAR Maps ...
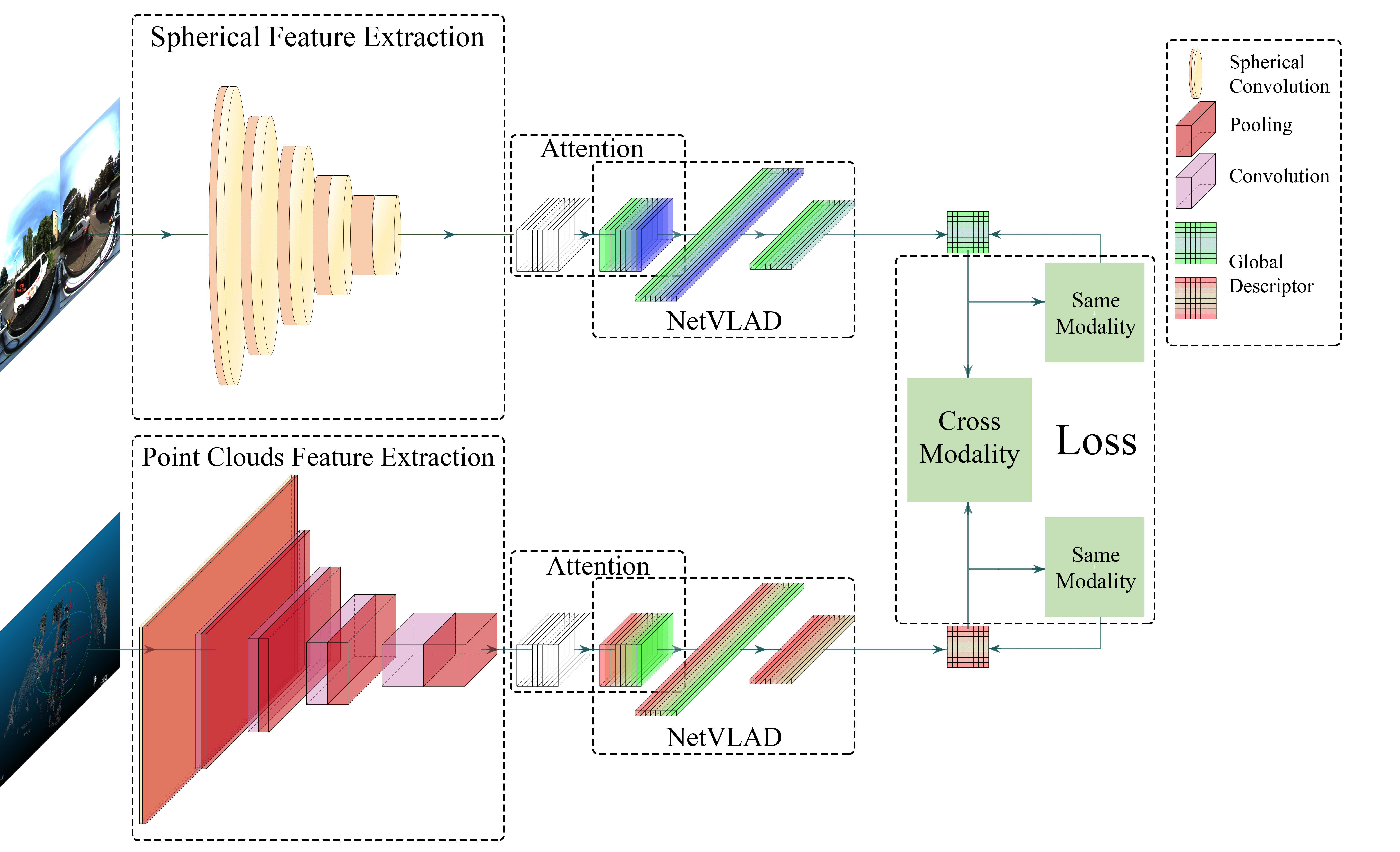
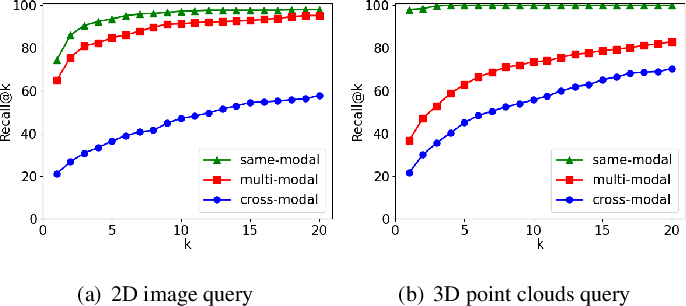
[2212.02757] Attention-Enhanced Cross-modal Localization Between 360 ...
Enhancing Cross-Modal Camera Image and LiDAR Data Registration Using ...
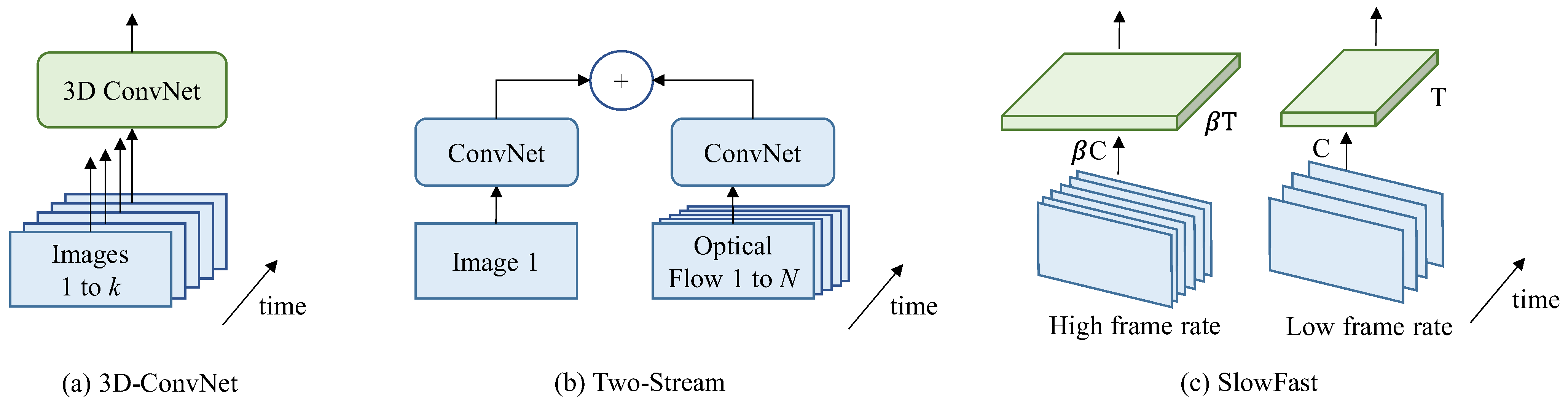
Figure 1 from Energy-Based Models for Cross-Modal Localization using ...
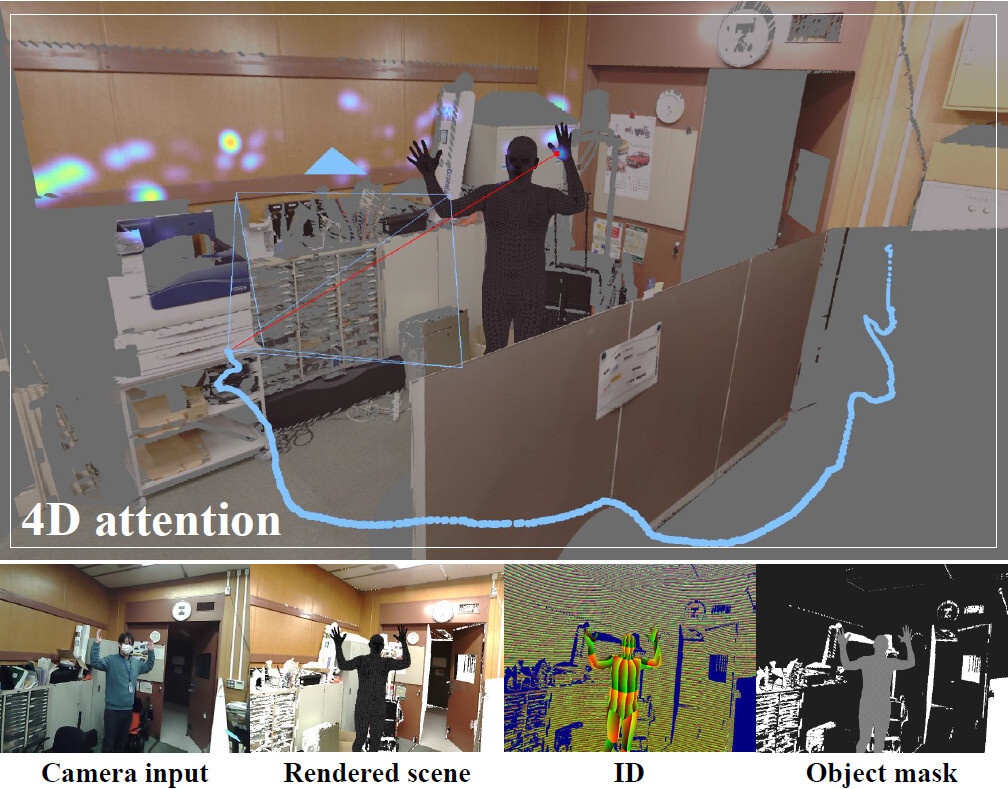
Figure 4 from LHMap-loc: Cross-Modal Monocular Localization Using LiDAR ...
A schematic of the cross-modal localization. The localization is ...
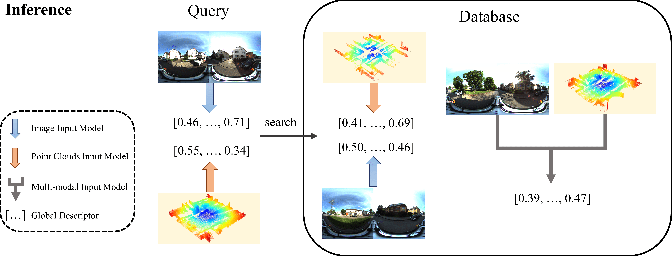
LIP-Loc: LiDAR Image Pretraining for Cross-Modal Localization - YouTube
Figure 1 from Cross-Modal Monocular Localization in Prior LiDAR Maps ...
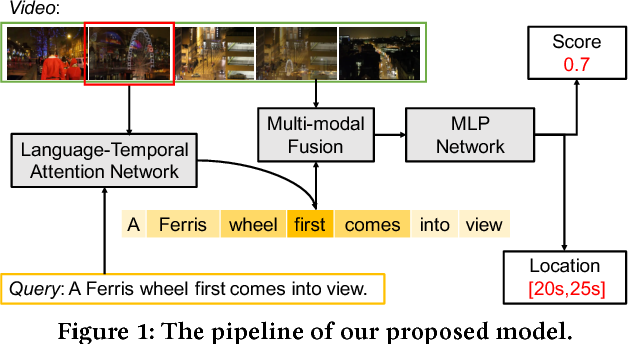
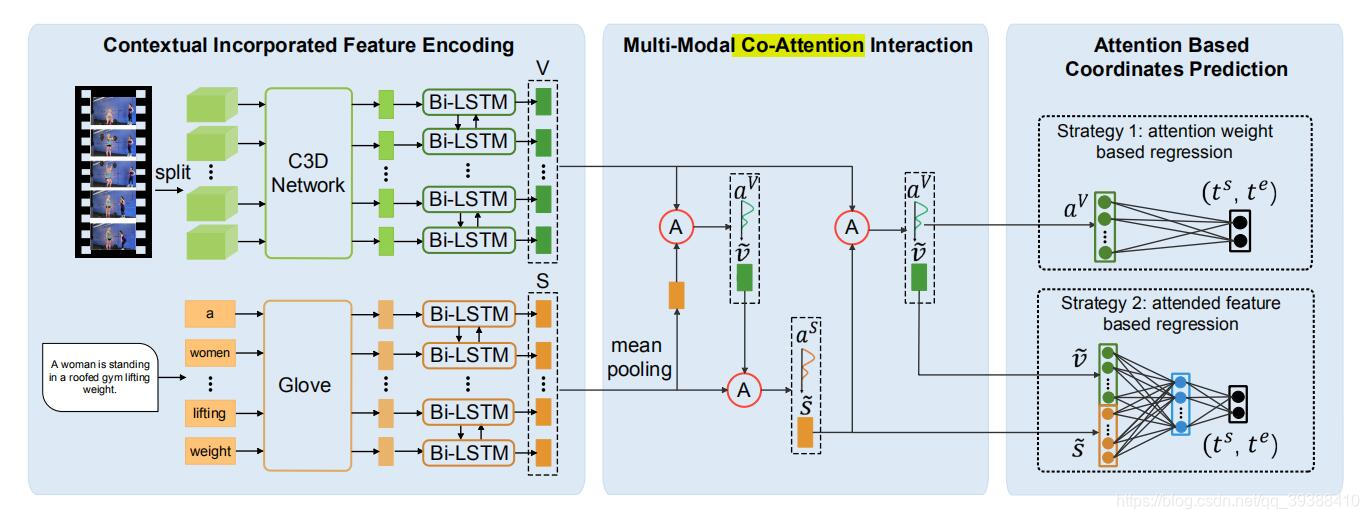
(PDF) Cross-modal Moment Localization in Videos
Cross-modal Data Collection System. RGB camera is placed above the ...
Frontiers | Cross-modal correspondence enhances elevation localization ...
Attention-Enhanced Cross-modal Localization Between 360 Images and ...
Figure 4 from Cross-Modal Monocular Localization in Prior LiDAR Maps ...
(PDF) Cross-Modal Localization via Sparsity
Cross-modal Moment Localization in Videos · Issue #4 · yawenzeng ...
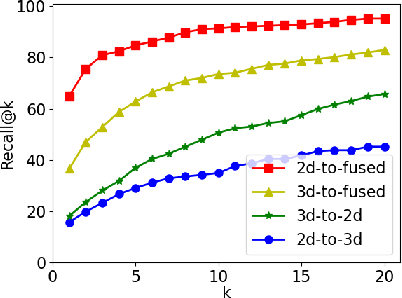
Figure 4 from Cross-Modal 2D-3D Localization with Single-Modal Query ...
(PDF) Towards Cross-Modal Forgery Detection and Localization on Live ...
RGB2LIDAR: Towards Solving Large-Scale Cross-Modal Visual Localization ...
A Sketch-Based Cross-Modal Retrieval Model for Building Localization ...
(PDF) Energy-Based Models for Cross-Modal Localization using ...
Figure 10 from Cross-Modal Semidense 6-DOF Tracking of an Event Camera ...
Figure 1 from Cross-modal Moment Localization in Videos | Semantic Scholar
Figure 1 from Cross-Modal 2D-3D Localization with Single-Modal Query ...
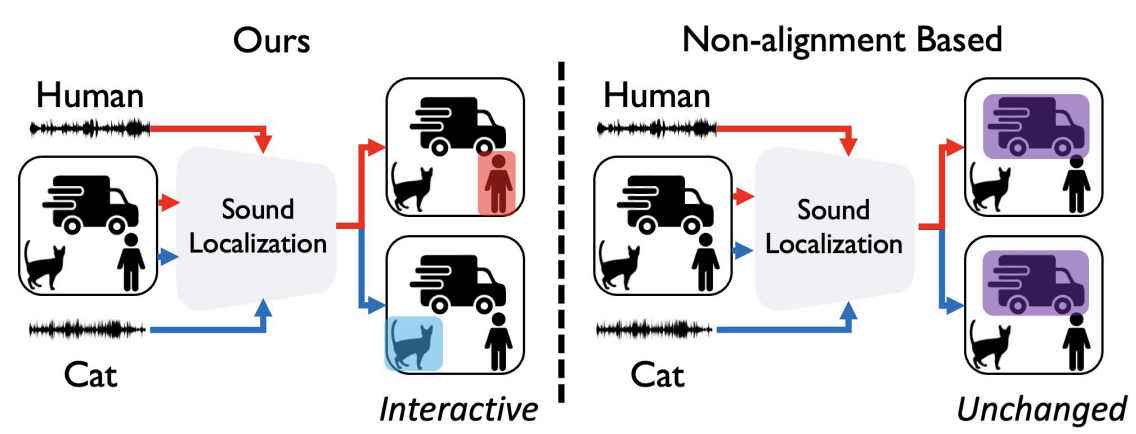
Sound Source Localization is All about Cross-Modal Alignment | DeepAI
VCG Harvard | Sound source localization is all about cross-modal alignment
(PDF) Cross-modal localization in hemianopia: new insights on ...
Cross-modal correspondence enhances elevation localization in visual-to ...
Seamless Fusion: Multi-Modal Localization for First Responders in ...
A Framework for Enabling Unpaired Multi-Modal Learning for Deep Cross ...
Results for cross-modal localization experiment. For each speaker ...
Cross-Modal Collaboration and Robust Feature Classifier for Open ...
A brief illustration of our cross-modal geo-localization approach by ...
Figure 1 from Cross-Modal Registration Using Adaptive Modeling in ...
An MIT And IBM Research Group Has Proposed A Cross-Modal Auditory ...
Infovaya • Presentation
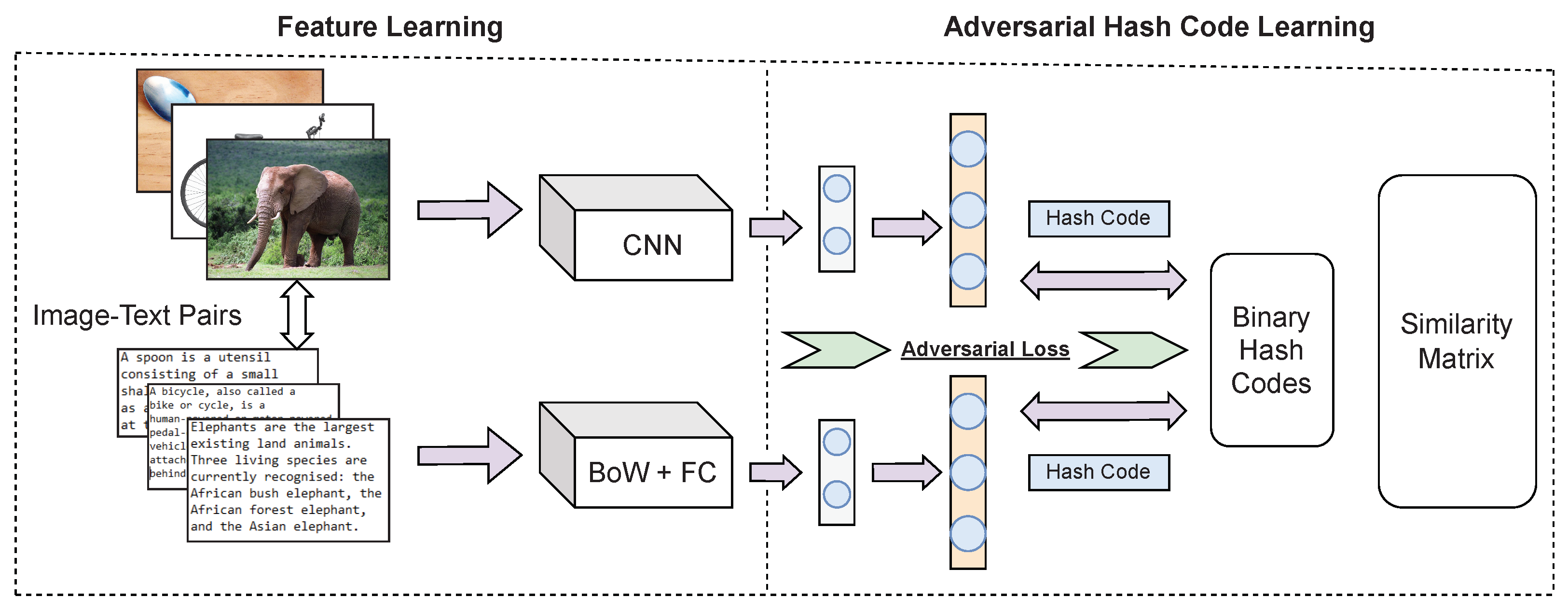
Figure 1 from Cross-Modal Label Contrastive Learning for Unsupervised ...
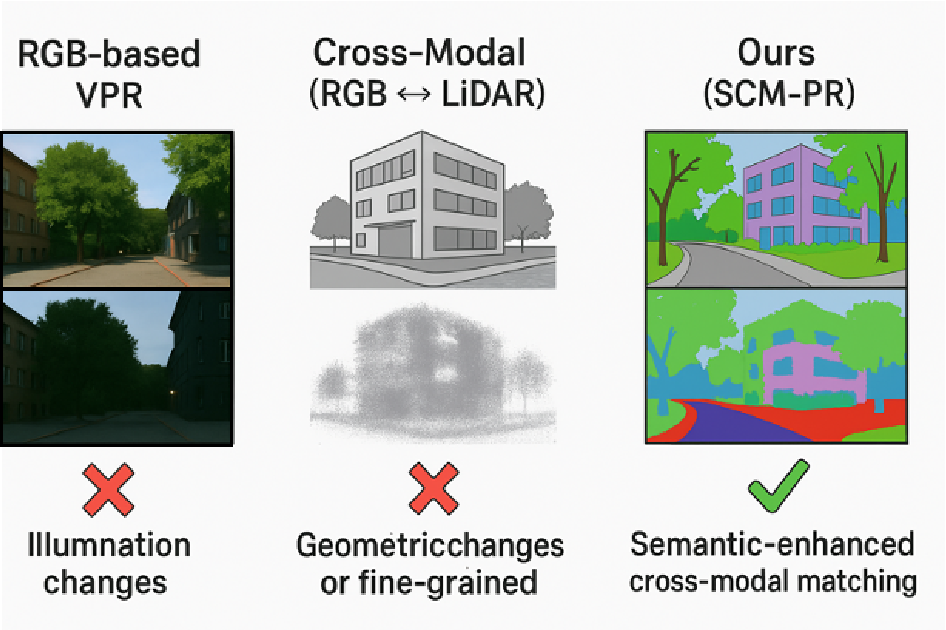
Figure 1 from Semantic-Enhanced Cross-Modal Place Recognition for ...
Cross-Modal Transformer-Based Streaming Dense Video Captioning with ...
Shuji Oishi @ AIST | C*: Cross-modal Simultaneous Tracking And ...
Semantic-Enhanced Cross-Modal Place Recognition for Robust Robot ...
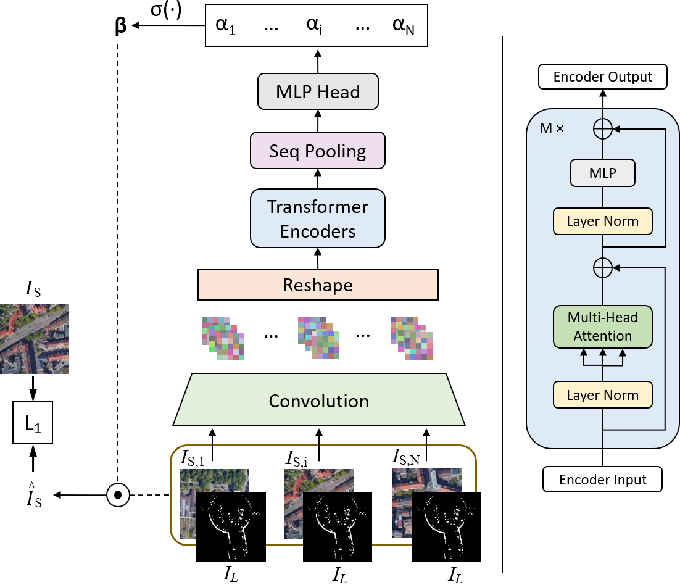
PR-CLIP: Cross-Modal Positional Reconstruction for Remote Sensing Image ...
C*: Cross-modal Simultaneous Tracking And Rendering for 6-DoF Monocular ...
Our paper, "LC2: LiDAR-Camera Loop Constraints For Cross-Modal Place ...
Figure 1 from Semantic Collaborative Learning for Cross-Modal Moment ...
The results of cross-modal localization. The second and third rows show ...
(PDF) (LC)$^2$: LiDAR-Camera Loop Constraints For Cross-Modal Place ...
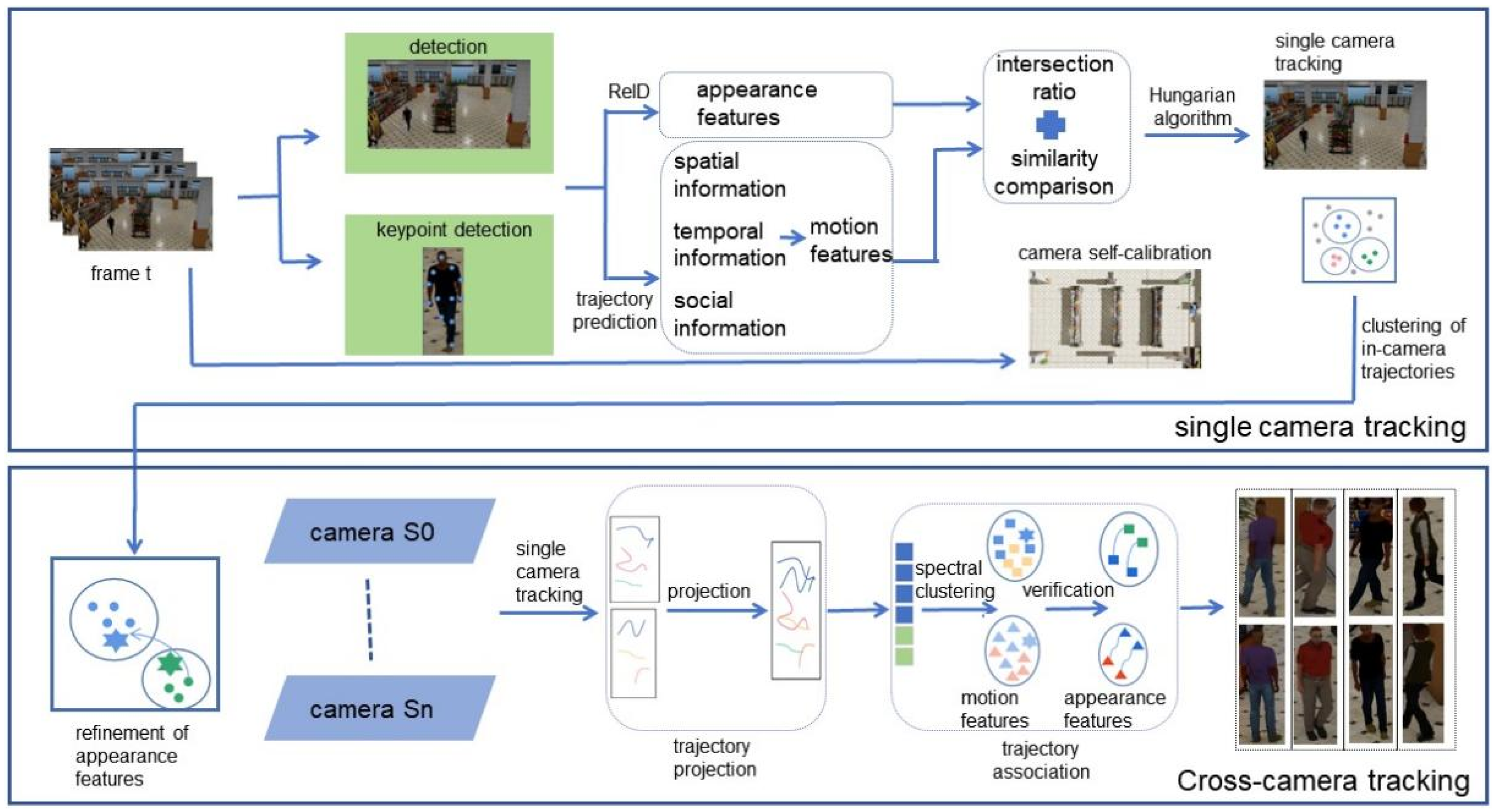
Cross-Camera Tracking Model and Method Based on Multi-Feature Fusion
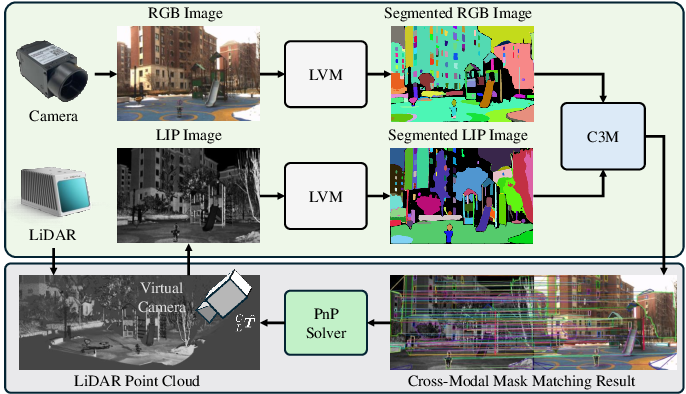
(PDF) Cross-Modal Visual Relocalization in Prior LiDAR Maps Utilizing ...
Figure 1 from Listen With Seeing: Cross-Modal Contrastive Learning for ...
Cross‐modal geo‐localization model architecture. The CNN shows the ...
The cross-modal attention model consisting of two branches, with the ...
A Cross-Modal Attention-Driven Multi-Sensor Fusion Method for Semantic ...
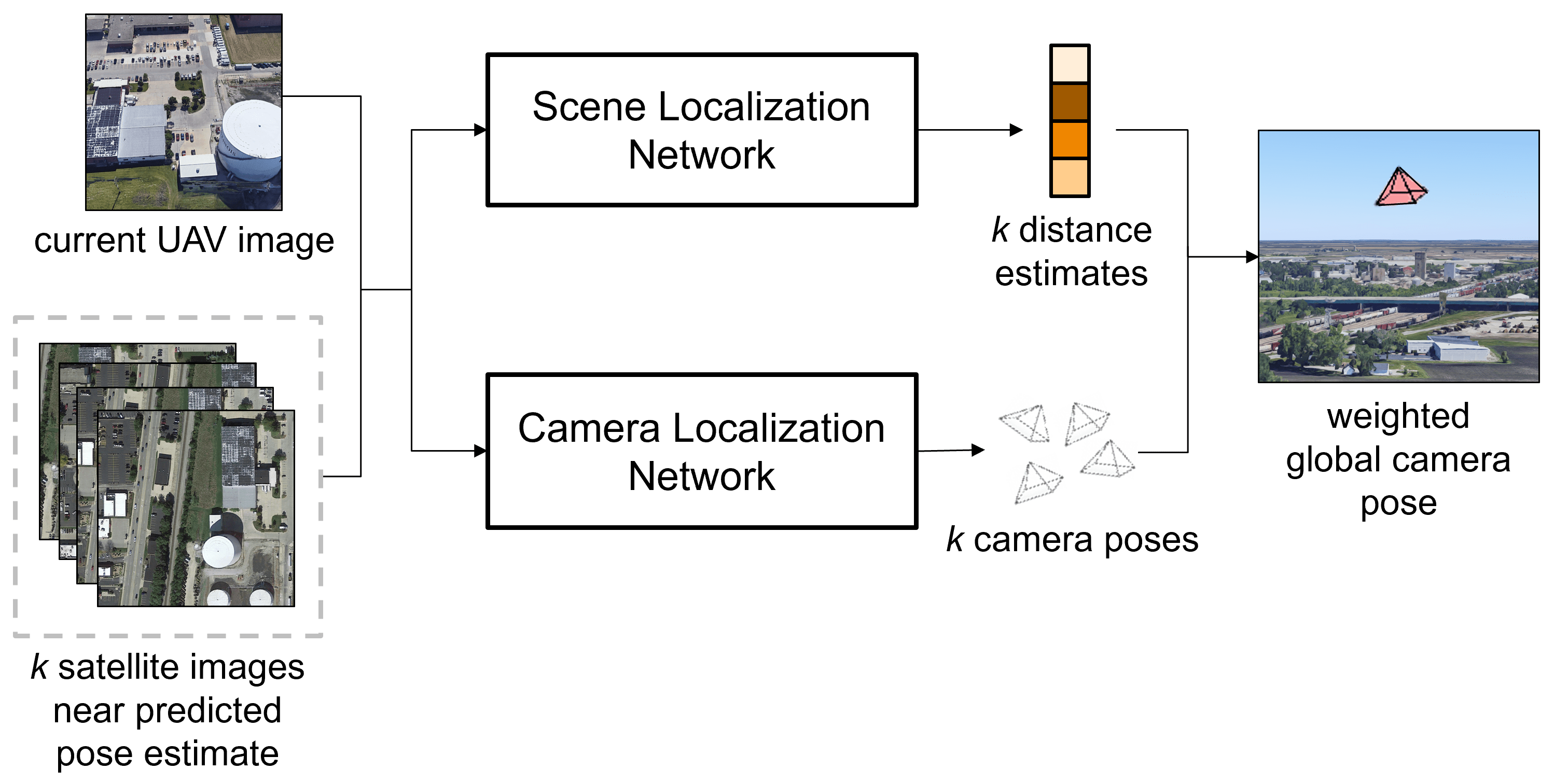
UAV Pose Estimation using Cross-view Geolocalization with Satellite ...
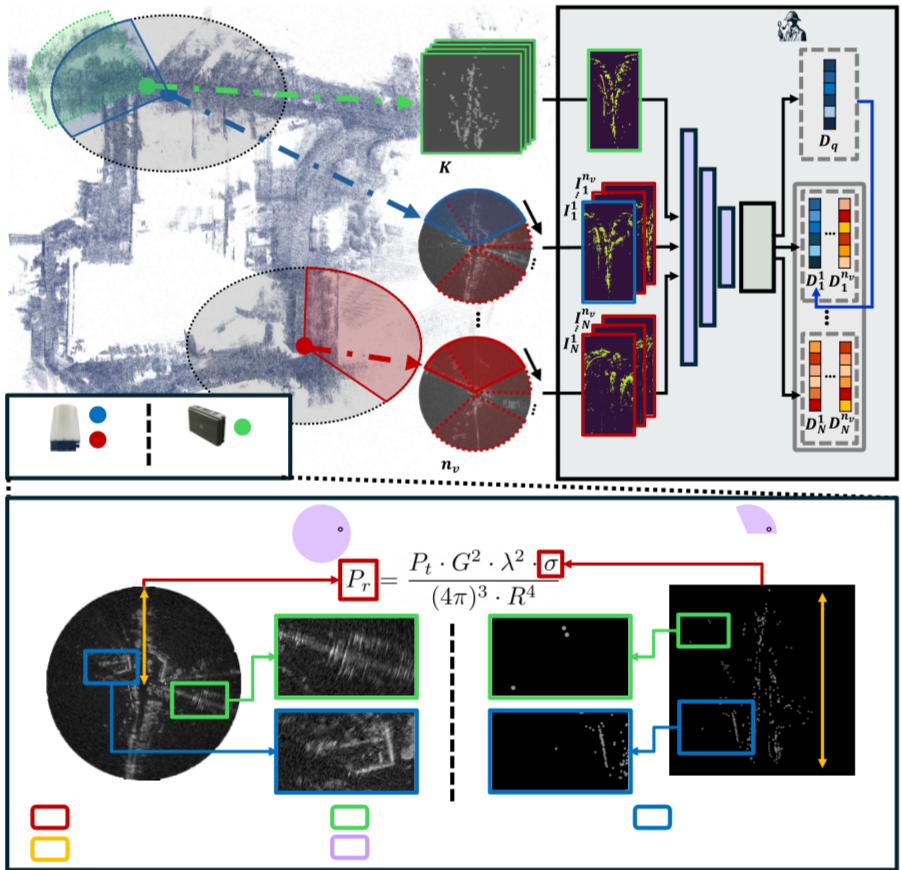
[논문 리뷰] SHeRLoc: Synchronized Heterogeneous Radar Place Recognition for ...
Cross-Modal Visual Relocalization in Prior LiDAR Maps Utilizing ...
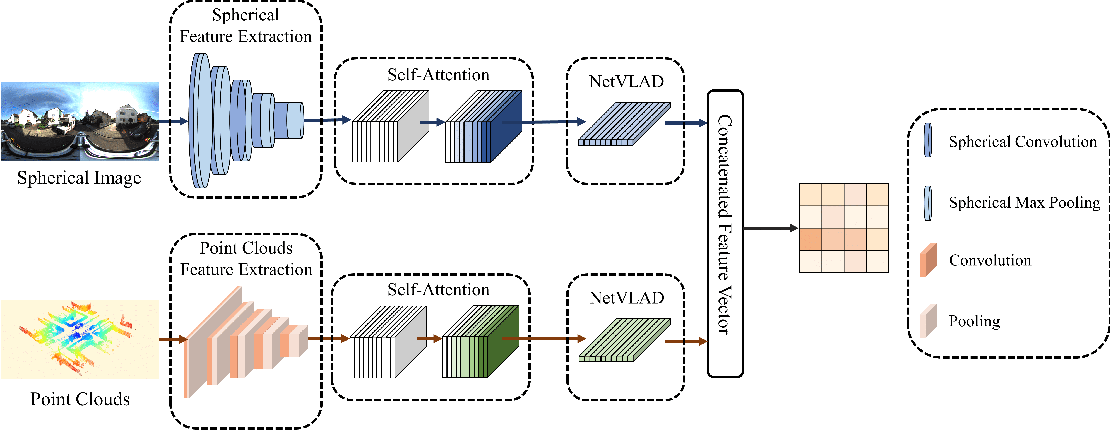
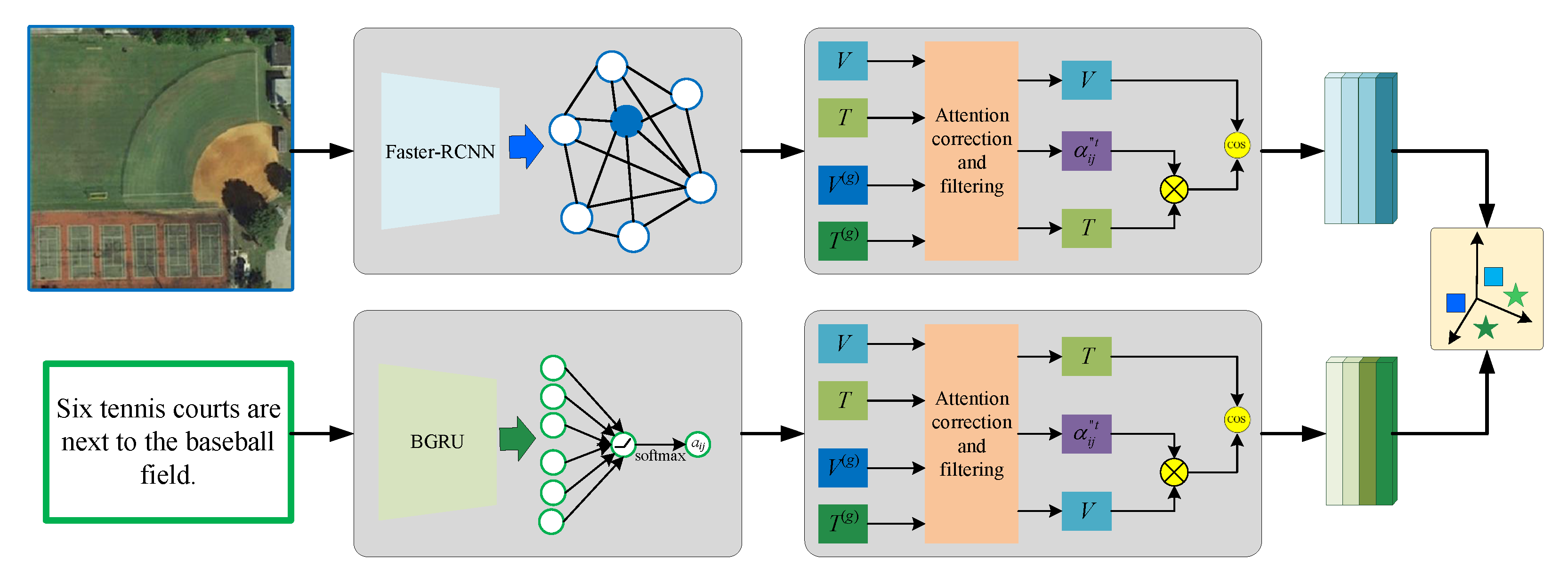
CMLocate: A cross‐modal automatic visual geo‐localization framework for ...
Cross-modal authentication and localization. | Download Scientific Diagram
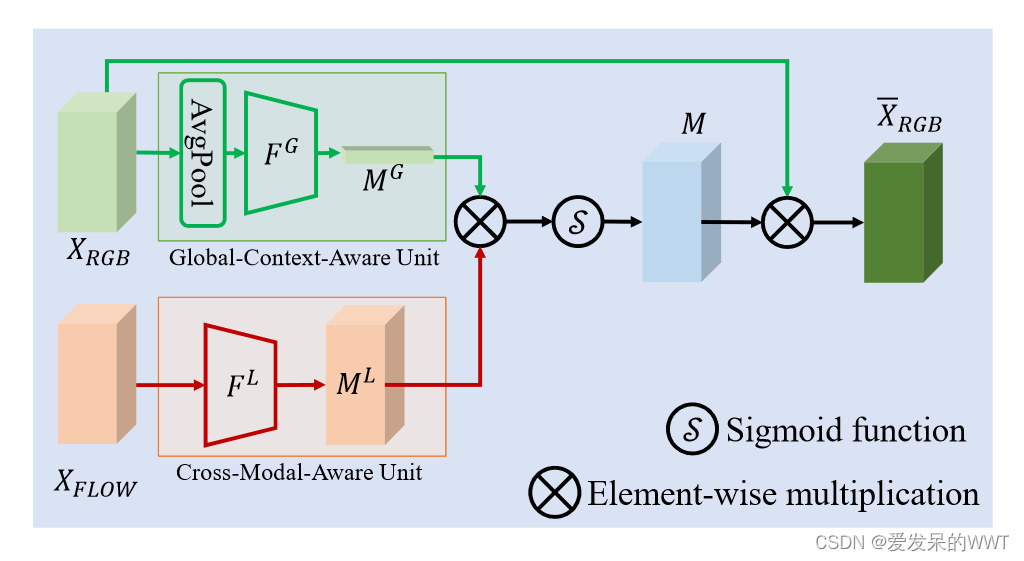
Camera-LiDAR Cross-Modality Fusion Water Segmentation for Unmanned ...
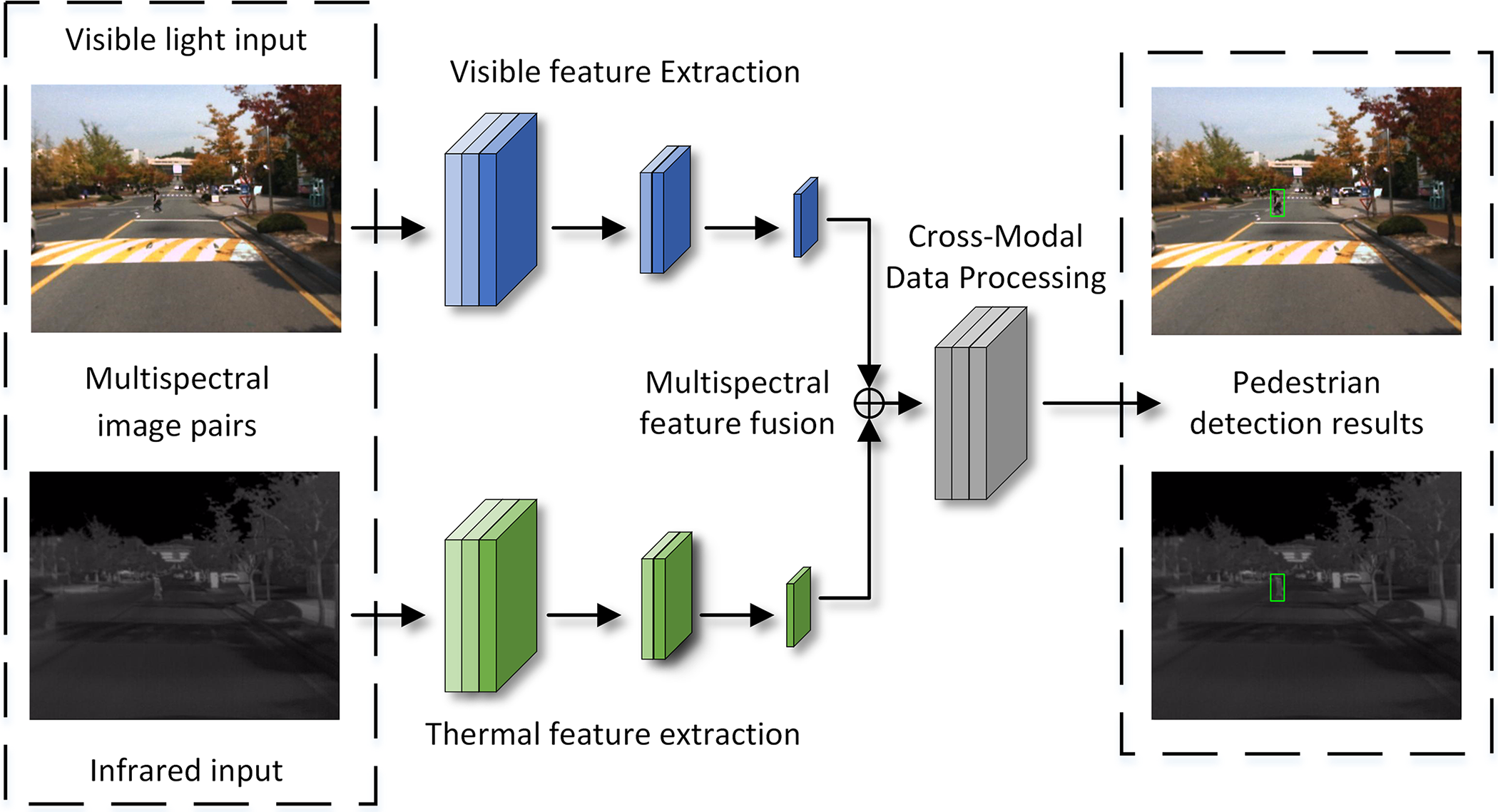
CMC | Free Full-Text | Lightweight Cross-Modal Multispectral Pedestrian ...
GitHub - Zhaozhpe/AE-CrossModal: Attention-Enhanced Cross-modal ...
Cross-Modal Alignment Enhancement for Vision–Language Tracking via ...
Cross-modal Video Moment Retrieval(跨模态视频时刻检索综述)-CSDN博客
Text-Driven Cross-Modal Place Recognition Method for Remote Sensing ...
[2309.12855] Cross-Modal Translation and Alignment for Survival Analysis
Figure 1 from Poses as Queries: End-to-End Image-to-LiDAR Map ...
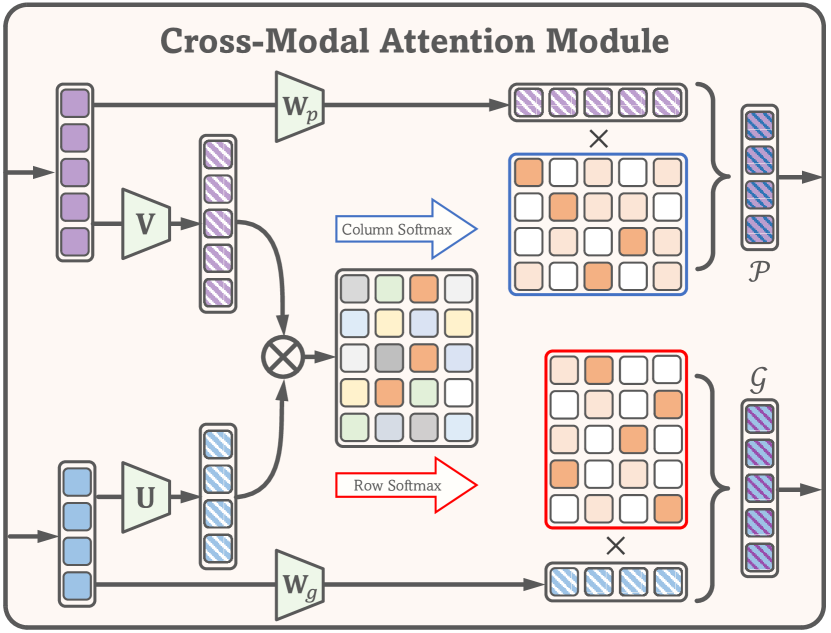
Remote Sensing Cross-Modal Text-Image Retrieval Based on Attention ...
(PDF) CMLocate: A cross‐modal automatic visual geo‐localization ...
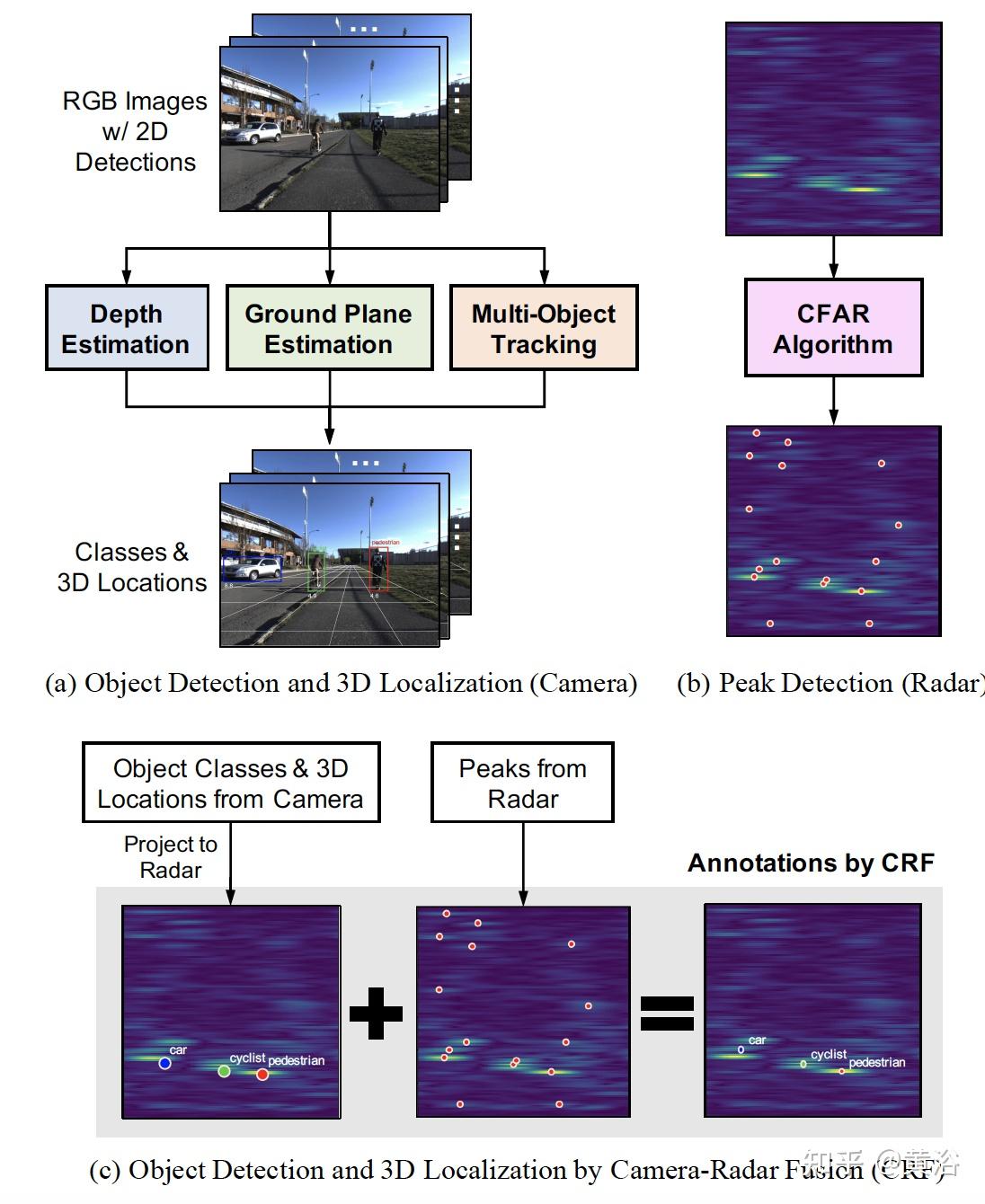
几个摄像头和雷达融合的目标检测方法 - 知乎
Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with ...
The overview of the cross-modal feature alignment method for zero-shot ...
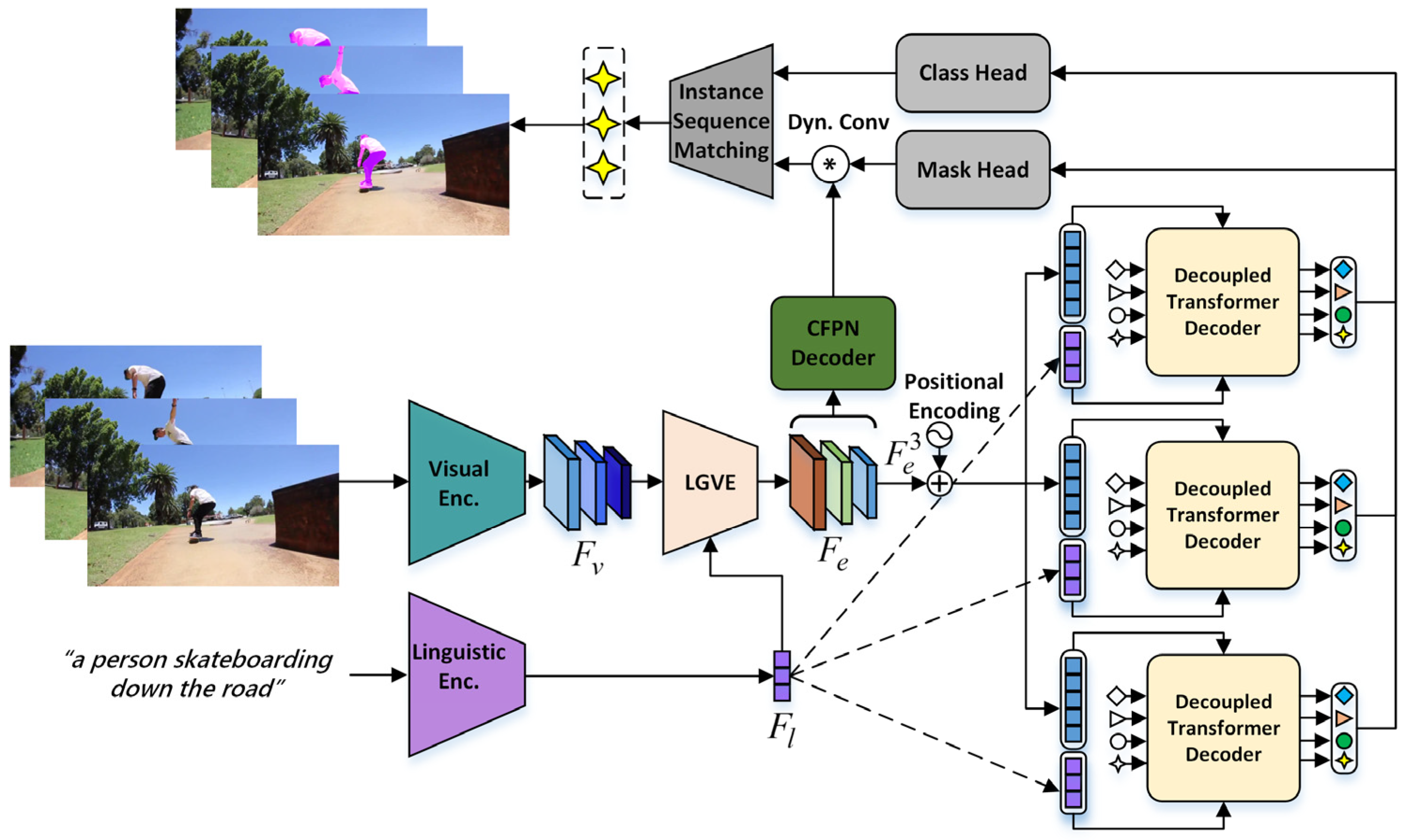
Decoupled Cross-Modal Transformer for Referring Video Object Segmentation
[論文レビュー] Contextual Cross-Modal Attention for Audio-Visual Deepfake ...
Cross-Modal Visible-to-Infrared Image Translation in Remote Sensing ...
Online,Target-Free LiDAR-Camera Extrinsic Calibration via Cross-Modal ...
Cross-modal contrastive learning of representations is proposed to ...
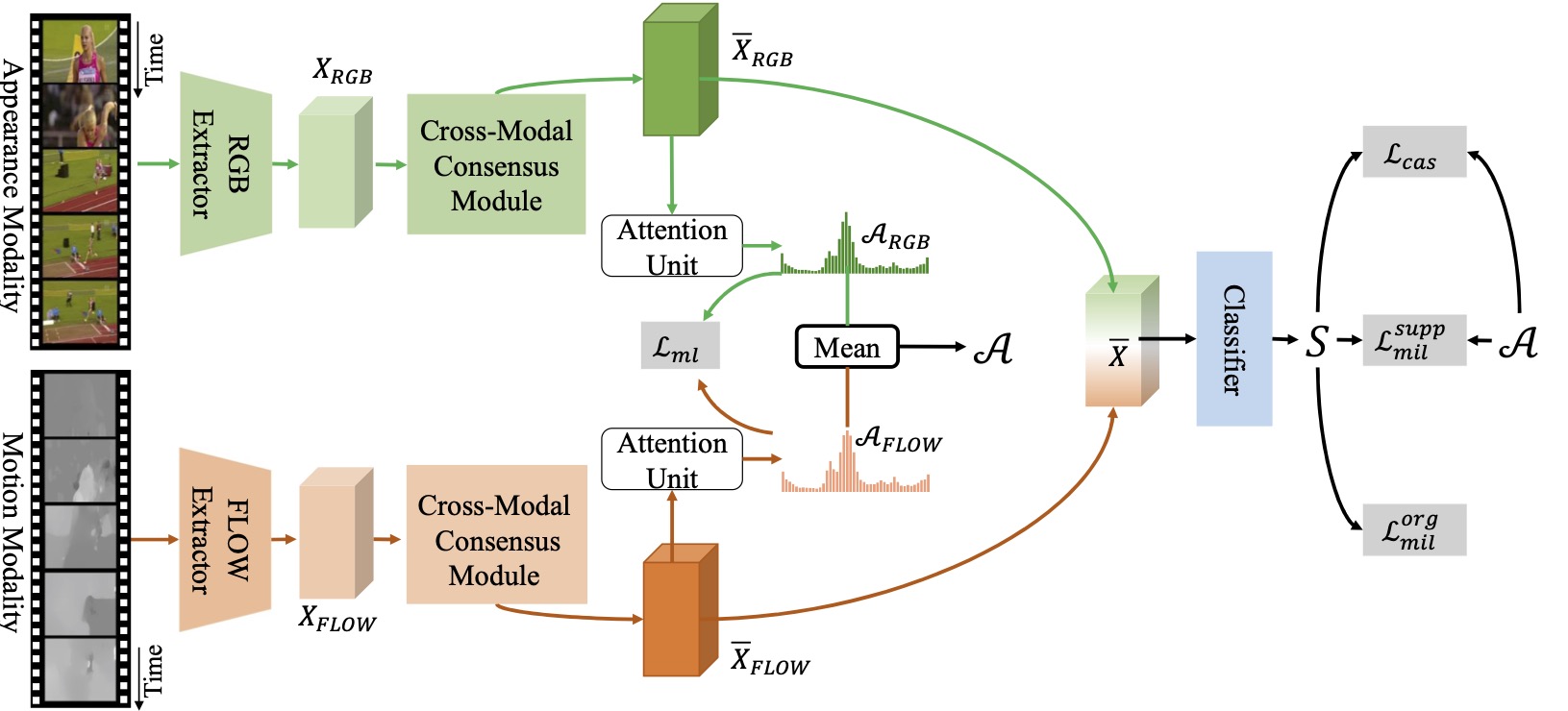
CO2Net: Cross-modal Consensus Network for Weakly Supervised Temporal ...
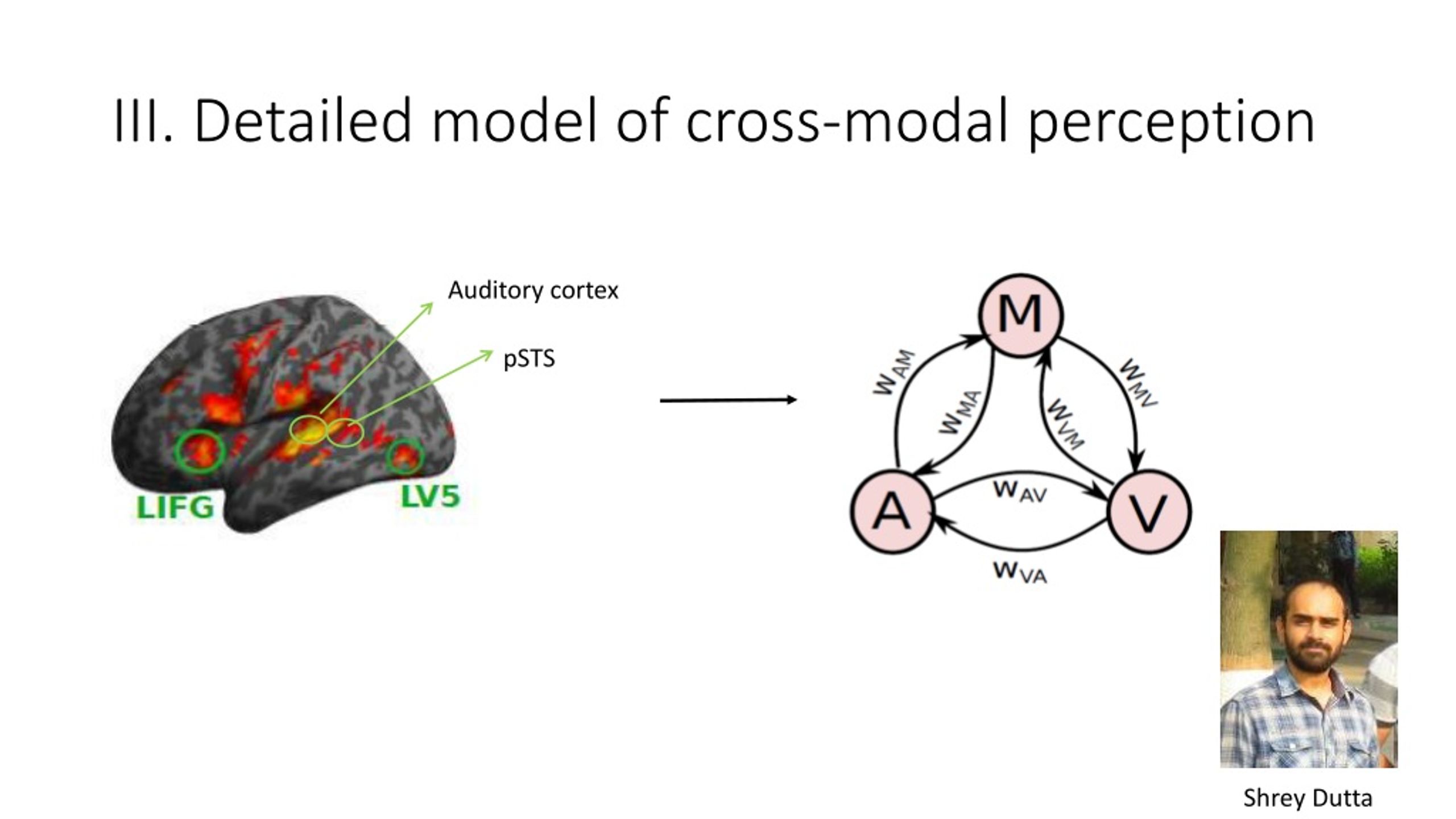
PPT - Teasing out the multi-scale representational space of cross-modal ...
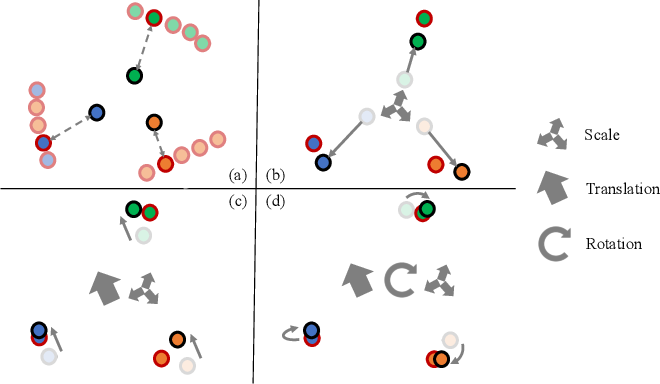
[2209.13801] Translation, Scale and Rotation: Cross-Modal Alignment ...
A Short Video Classification Framework Based on Cross-Modal Fusion
[2408.01532] Contextual Cross-Modal Attention for Audio-Visual Deepfake ...
Cross-modal correspondence between auditory pitch and visual elevation ...
LIP-Loc: LiDAR Image Pretraining for Cross-Modal Localization: Paper ...
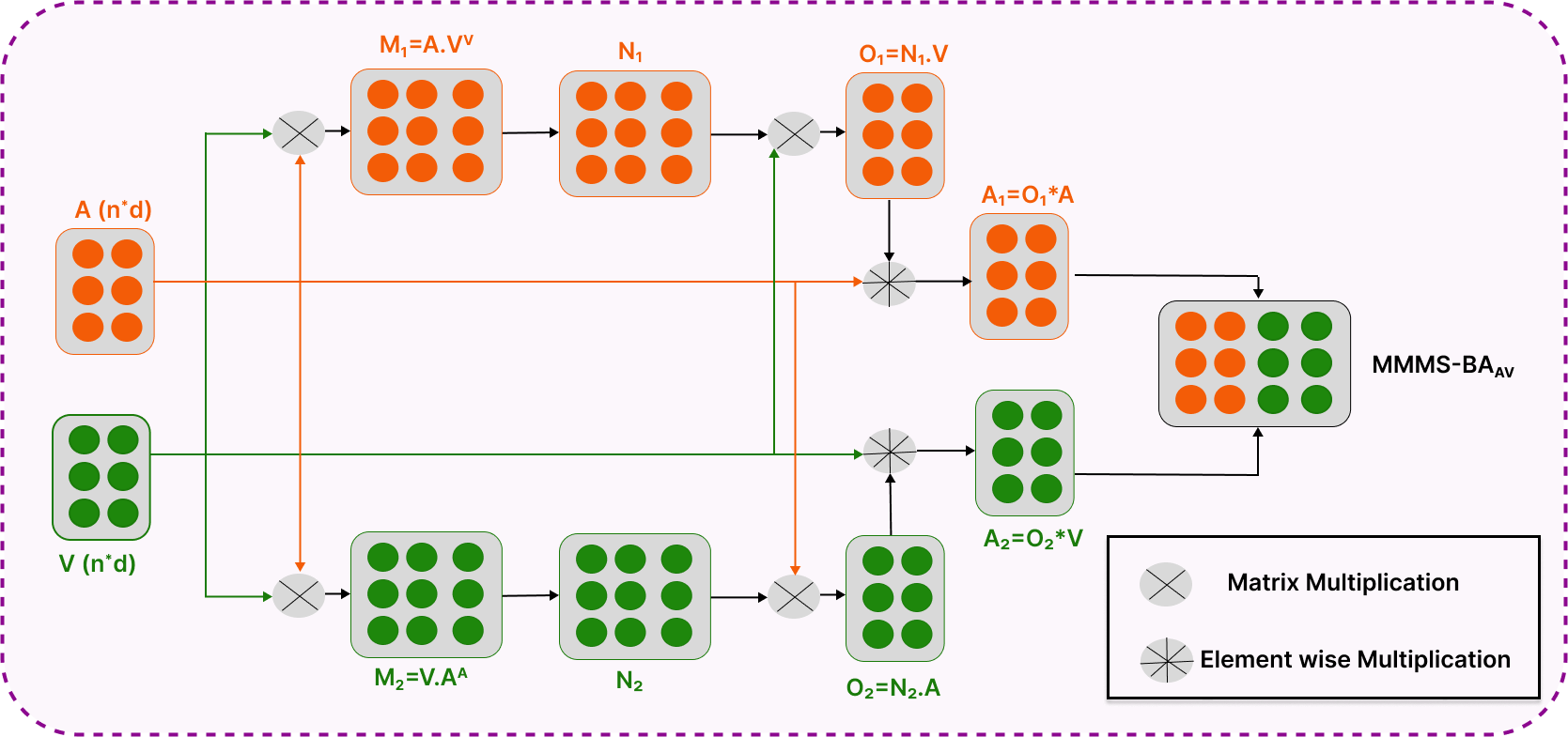
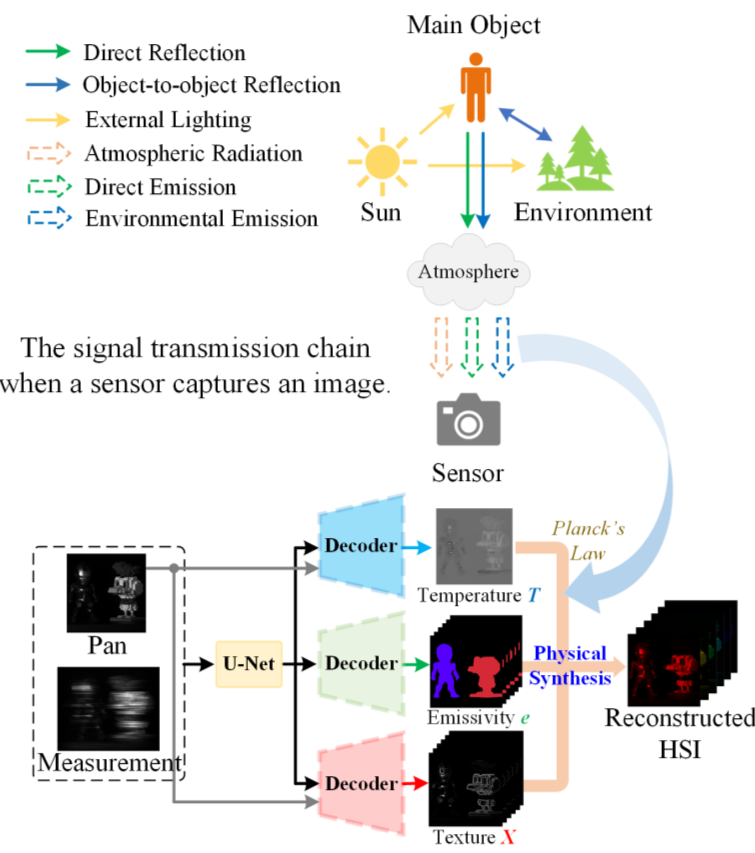
[论文评述] PCMamba: Physics-Informed Cross-Modal State Space Model for Dual ...
CO2-Net:Cross-Modal Consensus Network For Weakly Supervised Temporal ...
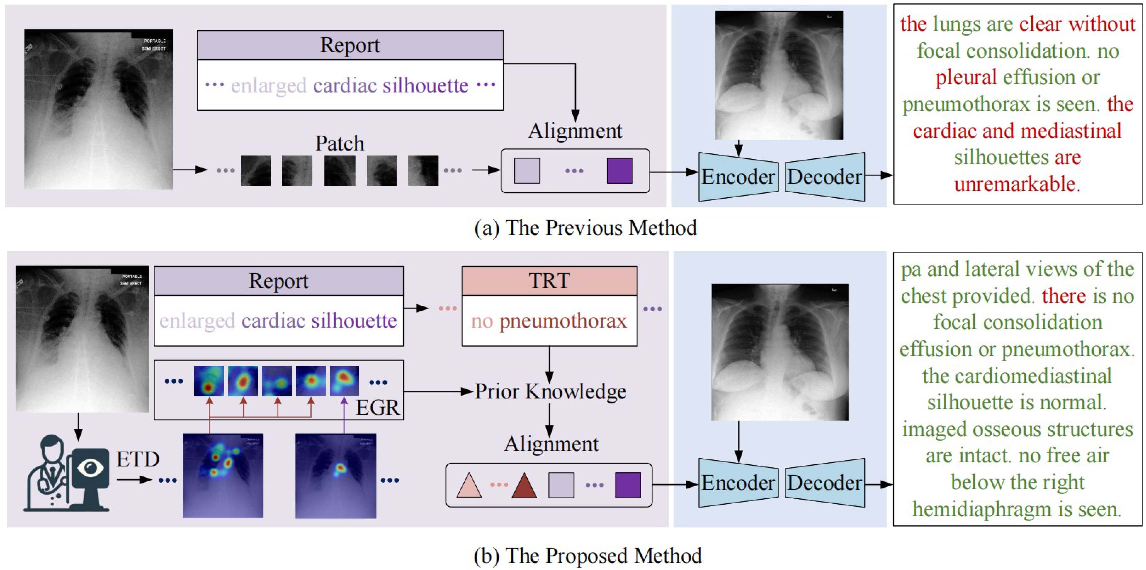
Figure 1 from Eye Gaze Guided Cross-Modal Alignment Network for ...